
Oleh Anthony Khong, Pendiri dan SVP Data Analytics di Zero One Group
Terjemahan oleh Abid Mukhlisin and Ayu Swasti
Zero One Technology dan Stream Intelligence telah bekerja sama untuk membangun solusi berbasis teknologi untuk salah satu pemain ritel terbesar di Indonesia. Di antara solusi yang dibangun adalah segmentasi pelanggan atau customer segmentation, berdasarkan machine learning. Setiap persona yang dihasilkan dari perkelompokan pelanggan tidak hanya mencerminkan perilaku belanja, namun juga kepribadian yang memperkaya narasi setiap segmen.
Algoritma yang kami gunakan bernama non-negative matrix factorisation, atau NMF. Pada dasarnya, NMF digunakan sebagai solusi di bidang computer vision, namun telah diterapkan untuk membangun sekelompok persona di berbagai studi. Algoritma tersebut bekerja dengan cara mempelajari sebuah konsep abstrak yang kemudian dirombak dan dikategorikan kembali sebagai sekelompok tema yang berkontras. Penjelasan lebih lanjut mengenai proses tersebut akan disediakan dalam blog ini.
Mengapa Segmentasi Pelanggan?
Segmentasi pelanggan adalah proses pembagian pelanggan menjadi beberapa kelompok yang memiliki karakteristik yang sama. Hal tersebut dapat membantu suatu perusahaan untuk mengerti pelanggan mereka lebih baik, dan seterusnya merancang strategi yang sesuai melalui berbagai metodologi termasuk brand positioning atau posisi merek, one-to-one marketing (pemasaran produk kepada pelanggan secara langsung), dan rekomendasi produk yang ditargetkan kepada setiap individu. Kadang, segmentasi bahkan dapat digunakan untuk mengidentifikasikan segmen yang sudah tidak aktif dalam portfolio pelanggan dan juga berguna untuk meluncurkan kampanye akuisisi yang meyakinkan (Groysberg, 2018).
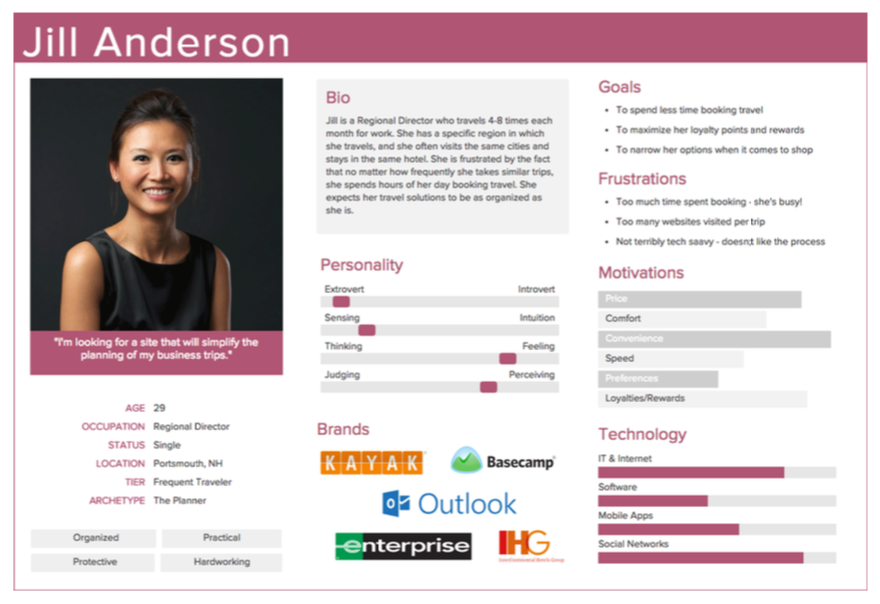
Segmentasi pelanggan juga dapat digunakan sebagai landasan untuk customer persona generation, didefinisikan sebagai “orang fiktif yang mewakili pelanggan atau kelompok pengguna yang mendasarinya”. Persona pelanggan menggambarkan suatu segmen menjadi kesatuan dengan visualisasi yang jelas, cerita latar belakang, dan transaksi pelanggan dengan penjual. Manfaat utama dari metode tersebut adalah untuk menyediakan model mental yang realistis dari berbagai jenis pelanggan untuk para pemimpin direksi utama di bisnis tersebut. Namun, penghasilan persona juga dikritik karena kekurangan verifikasi dan tindakannya.
Dalam situasi ini, kami menyaksikan munculnya perkumpulan data yang kaya seperti statistik keterlibatan aplikasi dan perilaku belanja, ditambah dengan peningkatan ketersediaan data analitik online seperti sumber data media sosial. Automated data-driven customer segmentation dapat digunakan untuk banyak penjual dengan cepat dan platform teknologi yang direalisasikan oleh banyaknya kumpulan data yang kaya. Ini sering kali merupakan hal yang mudah dan langkah pertama untuk memahami pelanggan mereka dengan lebih baik.
Non-Negative Matrix Factorisation
Lee dan Seung pertama kali memperkenalkan algoritma NMF pada tahun 1999 untuk mempelajari part-based representations dari sebuah objek, yang secara pada awalnya mengacu pada fitur gambar wajah dan fitur semantik teks.
Sama seperti teknik matriks factorisation lainnya termasuk principal component analysis (PCA) dan independent components analysis (ICA), algoritma NMF mengurai matriks menjadi dua non-negatif matriks yang lebih kecil, yang bila dikalikan menjadi sebuah matriks yang mendekati matriks aslinya:
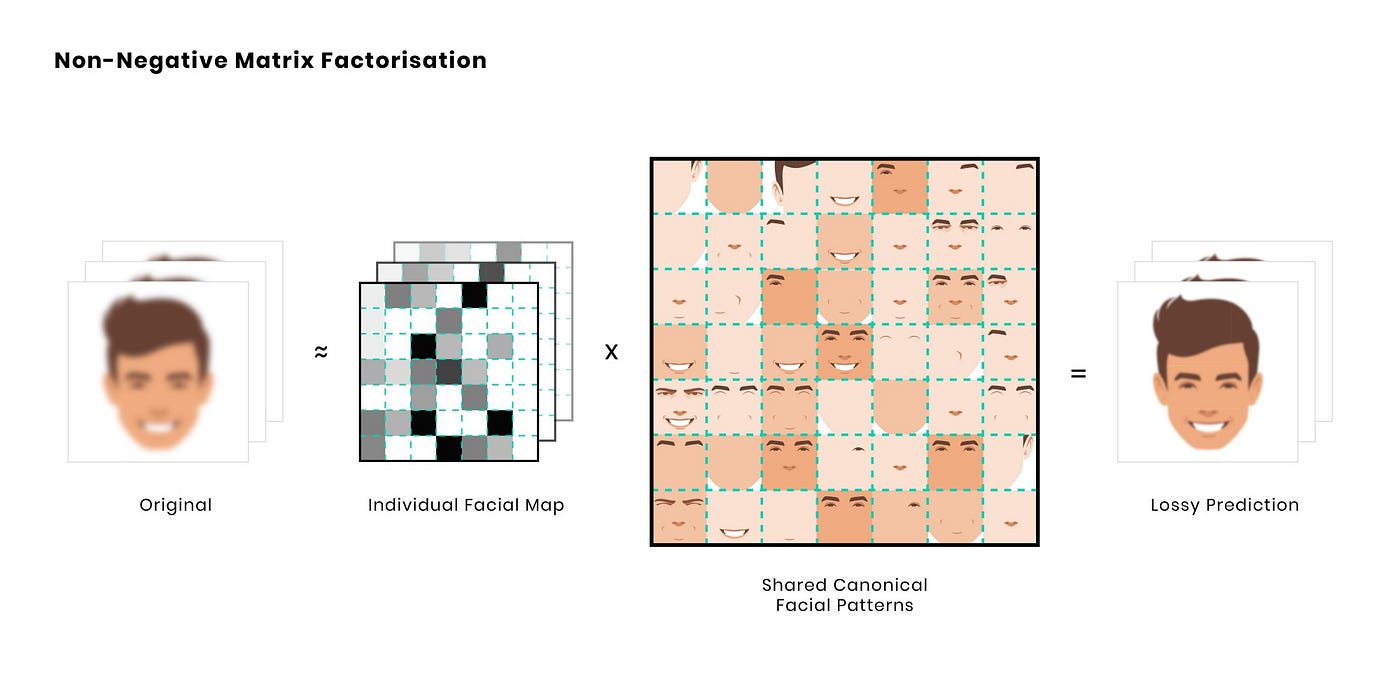
Mengambil contoh gambar wajah, algoritma NMF menguraikan banyak gambar wajah yang tersedia menjadi peta pola wajah individu dan pola wajah kanonik bersama. Tidak serupa dengan saat mempelajari eigenfaces melalui PCA, NMF hanya mengizinkan komponen aditif non-negatif, sehingga setiap pola wajah kanonik dapat menyerupai bagian wajah yang sebenarnya seperti mata, hidung, mulut, dan dagu. Satu karakteristik penting mengenai peta pola wajah individu adalah peta tersebut tersebar dimana-mana. Berarti, setiap peta individu membuang sebagian besar pola wajah, sehingga setiap wajah merupakan kombinasi dari hanya beberapa pola wajah terpilih.
Tapi apa yang membuat NMF cocok untuk segmentasi, dan bukan PCA? Untuk menjawab pertanyaan ini, bayangkan anda harus mengelompokkan orang berdasarkan gambar wajah mereka. Algoritma menemukan pola wajah kanonik tertentu, katakanlah, jenis hidung tertentu, dan mengidentifikasi setiap orang dengan hidung itu. Proses ini pada dasarnya mengelompokkan sejumlah orang dan membentuk segmen hidung yang serupa. Dengan mengulangi proses untuk semua pola wajah kanonik, kami memperoleh kumpulan segmen yang berdasarkan fitur wajah bersama. Proses ini tidak sama dengan PCA, khususnya karena PCA mengizinkan peta individu yang negatif dan yang tidak tersebar dimana-mana. Untuk apa artinya memamerkan eigenface tertentu, hanya untuk dikurangi dengan eigenface lainnya?
Segmentasi Pelanggan menggunakan NMF
Dua dekade kemudian, An et al. (2018) menggunakan algoritma NMF untuk mengelompokkan penonton akun YouTube AJ+. Dibanding menggunakan piksel gambar, mereka menggunakan tampilan video tertentu untuk menyusun matriks NMF. Dengan menggunakan enam pola perilaku kanonik, kelompok pemirsa teratas dari setiap pola perilaku menunjukkan segmentasi yang jelas dalam hal lokasi, usia, dan jenis kelamin.
Dengan studi ini, sangat mudah untuk melihat bagaimana teknik ini dapat diterjemahkan ke dalam segmentasi pelanggan di industri ritel. Daripada menggunakan piksel gambar atau tampilan video tertentu, kami dapat menggunakan perilaku belanja yang biasanya tersedia untuk banyak penjual. Secara khusus, kami dapat menggunakan total pengeluaran dari berbagai produk, kategori, waktu, dan metode pembayaran untuk menyusun matriks NMF kami.
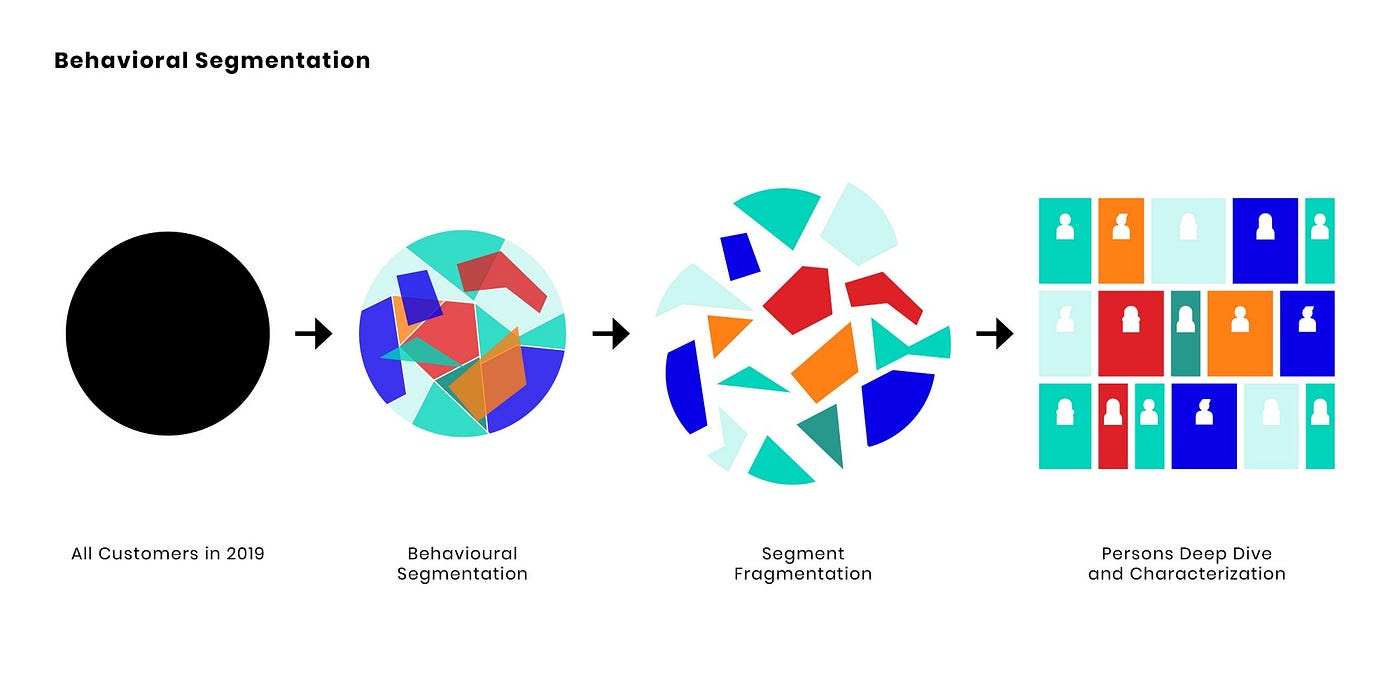
Untuk memahami apa yang dilakukan algoritma di tempat, NMF menggabungkan perilaku belanja yang terjadi dalam waktu bersamaan ke dalam set terpisah untuk membentuk pola belanja kanonik; sangat mirip dengan bagaimana NMF menemukan semacam hidung, mata, dagu, dan sebagainya. Dengan demikian, setiap pelanggan dapat diringkas dengan peta perilaku yang terpisah, yang mewakili kombinasi dari beberapa pola belanja.
Pola Belanja: Jembatan antara Pelanggan dan Perilaku
Salah satu cara untuk memikirkan pola belanja kanonik adalah bagaimana mereka dapat menghubungkan setiap pelanggan ke segmen masing-masing dan perilaku belanja. Ada beberapa cara di mana hubungan ini menjadi berguna.
Misalnya, kita ingin mengkategorikan pelanggan ke dalam segmen tertentu. Kami dapat mencari pola belanja teratas setiap pelanggan (yaitu operasi argmax):
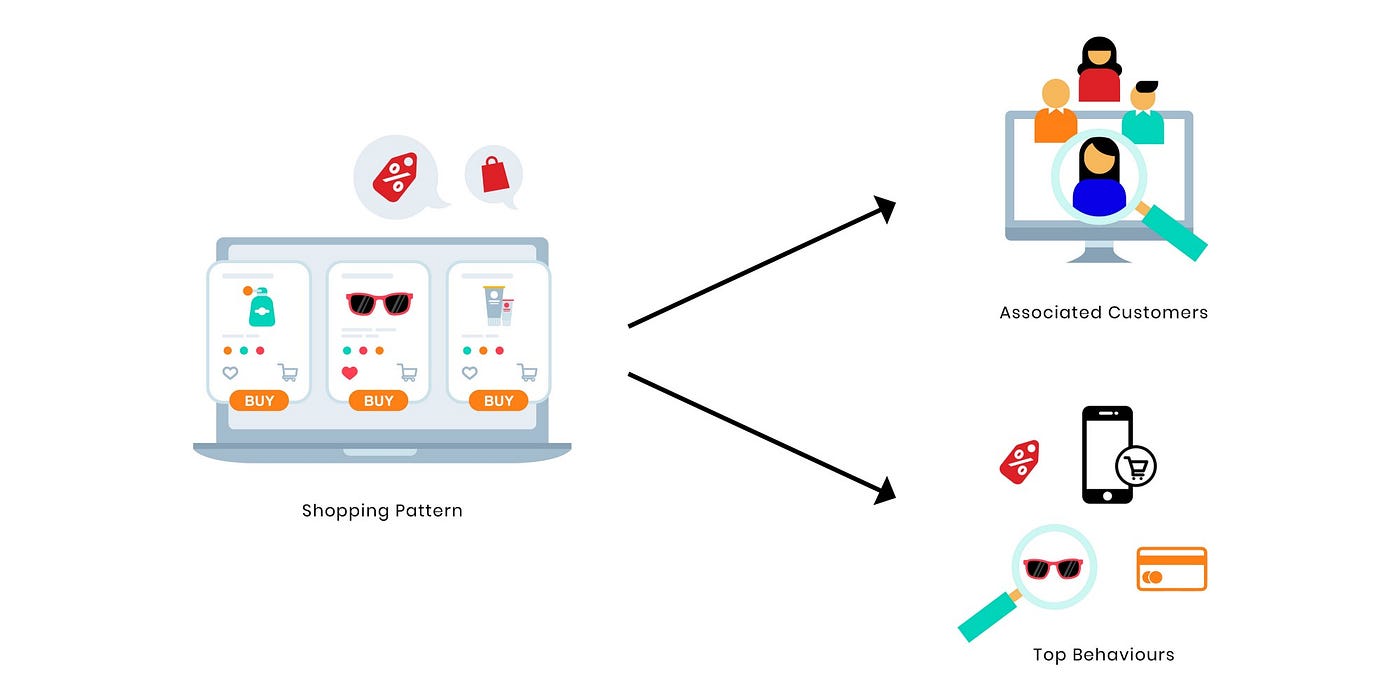
Contoh lain adalah untuk meringkas pola belanja pelanggan tertentu. Pertama-tama kita mencari, katakanlah, tiga pola belanja teratas dan kemudian mencari perilaku teratas dari setiap segmen..
Terakhir, untuk mengidentifikasi peluang penjualan silang, kami dapat mengidentifikasi pola belanja yang terkait dari produk dasar. Dari pola belanja tersebut, kami dapat mengidentifikasi produk terkait lainnya dan pelanggan yang secara signifikan menunjukkan pola belanja tersebut:

Kesimpulan
Tidak pernah semudah ini untuk mengakses data pelanggan dalam jumlah besar di dunia ritel. Beberapa penjual bahkan tanpa sadar duduk di atas harta karun berupa data mentah yang dapat ditangani, dianalisa, dan dibentuk menjadi wawasan yang dapat ditindaklanjuti. Kami telah menunjukkan satu contoh dimana kami telah memberikan wawasan seperti itu kepada klien kami.
Meskipun kami hanya berfokus pada aplikasi ritel, algoritma NMF telah diterapkan ke berbagai aplikasi dalam dekade terakhir ini. Misalnya, NMF telah digunakan untuk rekomendasi film, penemuan komunitas dan bahkan hyperspectral unmixing. Ini telah terbukti menjadi algoritma penemuan pola yang serbaguna!
NMF sama sekali bukan state-of-the-art machine learning algorithm. Namun NMF dapat menyelesaikan pekerjaan di tempat yang diperlukan. Di Zero One, kami terus melatih tim kami untuk menyederhanakan solusi kami, sambil mempertahankan ketelitian dan memperhatikan kebutuhan bisnis. Sederhana dan efektif, itulah yang kami suka!
Sumber Daya
- Almohri, Haidar, Ratna Babu Chinnam, and Mark Colosimo. “Data-Driven Analytics for Benchmarking and Optimizing Retail Store Performance.” arXiv preprint arXiv:1806.05563 (2018)
- An, Jisun, et al. “Customer segmentation using online platforms: isolating behavioral and demographic segments for persona creation via aggregated user data.” Social Network Analysis and Mining 8.1 (2018): 54.
- Gillis, Nicolas. “The why and how of nonnegative matrix factorization.” Regularization, optimization, kernels, and support vector machines 12.257 (2014): 257–291.
- Groysberg, Boris, and Annelena Lobb. “California Closets: Organizing the Customer Experience.” (2018).
- Lee, Daniel D., and H. Sebastian Seung. “Learning the parts of objects by non-negative matrix factorization.” Nature 401.6755 (1999): 788–791.
- Salminen, Joni, et al. “Generating cultural personas from social data: a perspective of Middle Eastern users.” 2017 5th International Conference on Future Internet of Things and Cloud Workshops (FiCloudW). IEEE, 2017.
- Salminen, Joni, et al. “Are personas done? Evaluating their usefulness in the age of digital analytics.” Persona Studies 4.2 (2018): 47–65.
- Salminen, Joni, Soon-gyo Jung, and Bernard J. Jansen. “The Future of Data-driven Personas: A Marriage of Online Analytics Numbers and Human Attributes.” 21st International Conference on Enterprise Information Systems, ICEIS 2019. SciTePress, 2019.
- Yang, Jaewon, and Jure Leskovec. “Overlapping community detection at scale: a nonnegative matrix factorization approach.” Proceedings of the sixth ACM international conference on Web search and data mining. 2013.
- Zhang, Sheng, et al. “Learning from incomplete ratings using non-negative matrix factorization.” Proceedings of the 2006 SIAM international conference on data mining. Society for Industrial and Applied Mathematics, 2006.
Follow Zero One Group at Instagram, Twitter, Facebook, and LinkedIn. Visit our website at www.zero-one-group.com


